











„NVIDIA“ tyrėjai stengiasi įgalinti keičiamą sintetinę generavimą robotų modelio mokymui. Šaltinis: NVIDIA
Pagrindinis robotikos iššūkis yra robotų mokymas atlikti naujas užduotis be didžiulių pastangų rinkti ir ženklinti duomenų rinkinius kiekvienai naujai užduotims ir aplinkai. Naujausias „NVIDIA“ tyrimų pastangas siekiama išspręsti šį iššūkį naudojant generatyvius AI, pasaulio fondo modelius, tokius kaip „Nvidia Cosmos“, ir duomenų generavimo brėžinius, tokius kaip NVIDIA Isaac GR00T-Mimic ir GR00T-Deams.
Neseniai „Nvidia“ apžvelgė, kaip tyrimai įgalina keičiamą sintetinių duomenų generavimo ir robotų modelio mokymo darbo eigą, naudojant „World Foundation“ modelius, tokius kaip:
- „DreamGen“: „Nvidia Isaac GR00T-Dreams“ projekto tyrimų fondas.
- GR00T N1: Atviro pagrindo modelis, leidžiantis robotams išmokti bendriesiems įgūdžių įvairiose užduotyse ir įgyvendinimo variantuose iš realių, žmogaus ir sintetinių duomenų.
- Latentinis veiksmas, išankstinis iš vaizdo įrašų: neprižiūrimas metodas, kuris mokosi robotams svarbių veiksmų iš didelio masto vaizdo įrašų, nereikalaujant rankinių veiksmų etikečių.
- „Sim-and real“ mokymas: mokymo metodas, kuriame derinami modeliuojami ir realaus pasaulio robotų duomenys, siekiant sukurti tvirtesnę ir pritaikomą robotų politiką.
Pasaulio fondo modeliai robotikai
„Cosmos World Foundation“ modeliai (WFMS) yra mokomi milijonų valandų realaus pasaulio duomenų, kad būtų galima numatyti būsimas pasaulio būsenas ir generuoti vaizdo įrašų sekas iš vieno įvesties vaizdo, leidžiančios robotams ir autonominėms transporto priemonėms numatyti būsimus įvykius. Šis nuspėjamosios galimybės yra labai svarbios sintetinių duomenų generavimo vamzdynams, palengvinant greitą įvairių, labai tikslumo mokymo duomenų kūrimą.
Šis WFM metodas gali žymiai paspartinti robotų mokymąsi, sustiprinti modelio tvirtumą ir sutrumpinti vystymosi laiką nuo mėnesių rankinių pastangų iki vos valandų, praneša NVIDIA.
Dreamgen
„DreamGen“ yra sintetinis duomenų generavimo vamzdynas, kuriame atsižvelgiama į dideles išlaidas ir darbas renkant didelio masto žmogaus teleoperacijos duomenis robotų mokymosi metu. Tai yra „NVIDIA Isaac GR00T-Dreams“, projekto, skirto generuoti didžiulius sintetinių robotų trajektorijos duomenis naudojant „World Foundation“ modelius, pagrindas.
Tradiciniams robotų fondų modeliams reikalingos išsamios rankinės demonstracijos kiekvienai naujai užduočiai ir aplinkai, o tai nėra keičiama. Modeliavimu pagrįstos alternatyvos dažnai kenčia nuo atotrūkio nuo SIM-TER-Real ir reikalauja sunkaus rankinio inžinerijos.
„DreamGen“ įveikia šiuos iššūkius naudodamas WFM, kad būtų sukurta realūs, įvairūs mokymo duomenys, turintys minimalų žmogaus indėlį. Šis požiūris įgalina mastelio robotų mokymąsi ir stiprią elgesio, aplinkos ir robotų įgyvendinimo variantų apibendrinimą.
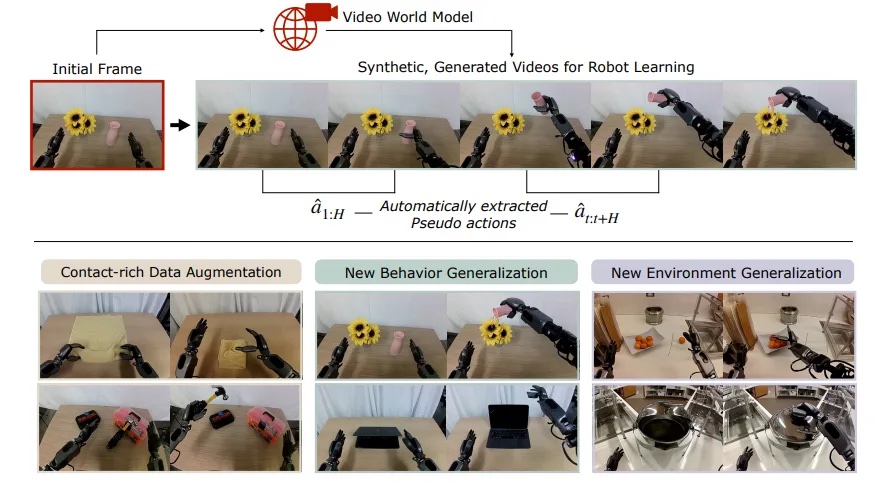
Apibendrinimas per „DreamGen“ sintetinį duomenų vamzdyną. | Šaltinis: NVIDIA
„DreamGen“ dujotiekį sudaro keturi pagrindiniai žingsniai:
- Pasaulio fondo po treniruotės modelis: Pritvirtinkite „World Foundation“ modelį, pavyzdžiui, „Cosmos-Predict2“, prie tikslinio roboto, naudodamiesi nedideliu realių demonstracijų rinkiniu. „Cosmos-Predict2“ gali generuoti aukštos kokybės vaizdus iš „Text“ (teksto iki žaidimo) ir vaizdinių modeliavimų iš vaizdų ar vaizdo įrašų (vaizdo įrašų į pasaulį).
- Generuokite sintetinius vaizdo įrašus: Norėdami sukurti įvairius, fotorealistinius robotų vaizdo įrašus naujoms užduotims ir aplinkai nuo vaizdo ir kalbos raginimų, naudokite po apmokytą modelį.
- Ištraukite pseudo veiksmus: Taikykite latentinį veiksmo modelį arba atvirkštinį dinamikos modelį (IDM), kad šie vaizdo įrašai paverstų paženklintomis veiksmo sekomis (nervų trajektorijomis).
- Treniruokis robotų politika: Naudokite gautas sintetines trajektorijas, kad išmokytumėte vizuomotorinę politiką, kad robotai galėtų atlikti naują elgesį ir apibendrinti iki nematytų scenarijų.
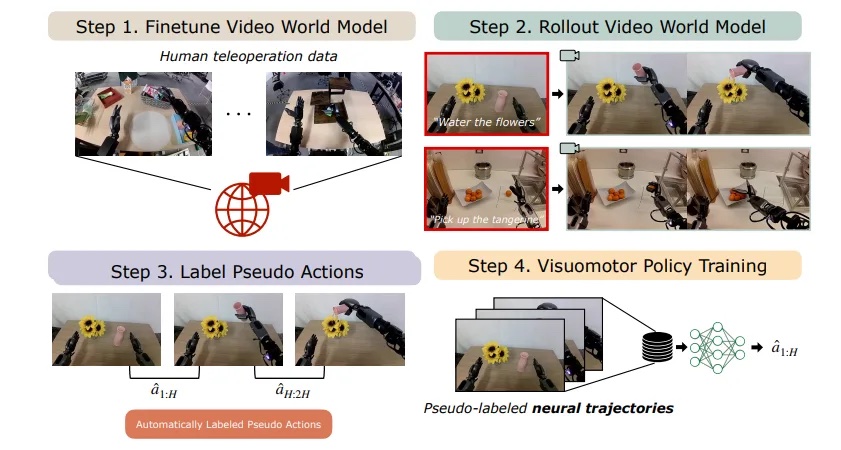
„DreamGen“ vamzdyno apžvalga. | Šaltinis: NVIDIA
„DreamGen“ suolelis
„DreamGen“ suolelis yra specializuotas etalonas, skirtas įvertinti, kaip efektyviai vaizdo generaciniai modeliai prisitaiko prie konkrečių robotų įgyvendinimo variantų, tuo pačiu vidaus ir nelanksčios kūno fizikos ir apibendrinant naujus objektus, elgesį ir aplinką. Tai išbando keturis pirmaujančius pasaulio pamatų modelius – „Nvidia Cosmos“, „Wan 2.1“, „Hunyuan“ ir „Cogvideox“ – išmatuoja dvi kritines metrikas:
- Instrukcija Toliau: „DreamGEN“ suolelis įvertina, ar sugeneruoti vaizdo įrašai tiksliai atspindi užduoties instrukcijas, tokias kaip „Svogūno pasiimk“, įvertintas naudojant matymo kalbos modelius (VLM), tokius kaip „QWEN-VL-2.5“ ir „Žmogaus anotatoriai“.
- Fizika seka: Tai kiekybiškai įvertina fizinį realizmą naudojant tokias priemones kaip vaizdo-fizika ir QWEN-VL-2.5, siekiant užtikrinti, kad vaizdo įrašai paklustų realaus pasaulio fizikai.
Kaip matyti žemiau esančiame diagramoje, modeliai, kuriuose rodomas aukštesnis „DreamGen“ stendas-tai reiškia, kad jie sukuria realistiškesnius ir instrukcijas sekančius sintetinius duomenis-tvirtai lemia geresnį našumą, kai robotai yra treniruojami ir išbandomi atliekant realias manipuliavimo užduotis. Šis teigiamas ryšys rodo, kad investavimas į stipresnius WFM ne tik pagerina sintetinių mokymo duomenų kokybę, bet ir tiesiogiai paverčia pajėgesnius ir pritaikomus robotus praktikoje.
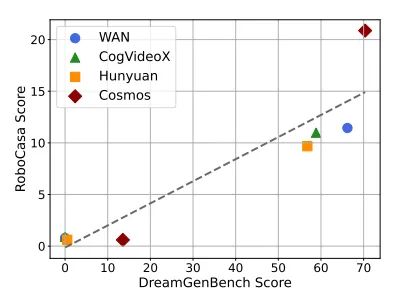
Teigiamas našumo koreliacija tarp „DreamGen“ suolo ir robocasa. | Šaltinis: NVIDIA
„Nvidia Isaac Gr00T-Dreams“
„Isaac GR00T-Dreams“, remiantis „DreamGen Research“, yra darbo eiga kuriant didelius sintetinių trajektorijos duomenų duomenų rinkinius robotų veiksmams. Šie duomenų rinkiniai yra naudojami fiziniams robotams treniruotis, o taupant daug laiko ir rankomis, palyginti su realaus pasaulio veiksmų duomenų rinkimu, teigia NVIDIA.
GR00T-DREAMS naudoja „CosMOS Predict2 WFM“ ir „Cosmos“ priežastį, kad būtų galima generuoti duomenis skirtingoms užduotims ir aplinkai. Kosmoso priežasčių modeliuose yra multimodalinis LLM (didelės kalbos modelis), kuris sukuria fiziškai pagrįstus atsakymus į vartotojų raginimus.

Pamatų modeliai ir darbo eigos robotų treniruotėms
„Vision-Language-Action“ (VLA) modeliai gali būti išmokyti po duomenų, sugeneruotų iš WFMS, kad būtų įgalintas naujas elgesys ir operacijos nematytoje aplinkoje, paaiškinta NVIDIA.
„NVIDIA Research“ panaudojo GR00T-DREAMS projektą, kad būtų galima generuoti sintetinius mokymo duomenis, kad būtų sukurta GR00T N1.5-GR00T N1 atnaujinimas vos per 36 valandas. Šis procesas būtų užtrunkantis beveik tris mėnesius, naudojant rankinį duomenų duomenų rinkimą.
GR00T N1, atviro fondo modelis generaliniams humanoidiniams robotams, žymi didelį proveržį robotikos ir AI pasaulyje, pranešė bendrovė. Sukurta ant dvigubos sistemos architektūros, įkvėptos žmogaus pažinimo, GR00T N1 suvienija regėjimą, kalbą ir veiksmą, leidžiančią robotams suprasti instrukcijas, suvokti jų aplinką ir vykdyti sudėtingas, kelių žingsnių užduotis.
GR00T N1 remiasi tokiais metodais kaip LAPA (latentinis veiksmas, išankstinis bendrųjų veiksmų modeliams), kad galėtų mokytis iš nepaženklintų žmogaus vaizdo įrašų ir metodų, tokių kaip „Sim-and-Real Co-Trenching“, kuris sujungia sintetinius ir realaus pasaulio duomenis, kad būtų galima stipresnį apibendrinimą. Vėliau sužinosime apie „LAPA“ ir „Sim-and Real“ treniruotes.
Derindamas šias naujoves, „Gr00T N1“ ne tik vykdykite instrukcijas ir vykdykite užduotis-tai nustato naują etaloną to, ką generalistiniai humanoidiniai robotai gali pasiekti sudėtingoje, nuolat kintančioje aplinkoje, sakė NVIDIA.
„Gr00T N1.5“ yra patobulintas atvirojo pagrindų modelis, skirtas generaliniams humanoidiniams robotams, remiantis originaliu GR00T N1, kuriame yra rafinuotas VLM, apmokytas įvairių realių, modeliuojamų ir svajonių generuojamų sintetinių duomenų derinio.
Patobulinus architektūrą ir duomenų kokybę, „Gr00T N1.5“ suteikia aukštesnius sėkmės procentus, geresnį kalbos supratimą ir stipresnį apibendrinimą naujiems objektams ir užduotims, todėl tai yra tvirtesnis ir pritaikomas sprendimas pažengusiems robotų manipuliacijai.
Latentinis veiksmas, išankstinis vaizdo įrašų
„LAPA“ yra neprižiūrimas metodas, skirtas išankstiniam VLA modelių paruošimui, kuris pašalina brangių, rankiniu būdu paženklintų roboto veiksmo duomenų poreikį. Užuot pasikliaudami dideliais, anotuojamais duomenų rinkiniais, kurie yra brangūs ir reikalaujantys daug laiko, „LAPA“ naudoja daugiau nei 181 000 nepaženklintų interneto vaizdo įrašų, kad išmoktų veiksmingų reprezentacijų.
Šis metodas suteikia 6,22% našumo padidėjimą, palyginti su pažangiais modeliais, atliekant realaus pasaulio užduotis, ir pasiekia daugiau nei 30 kartų didesnį išankstinio nustatymo efektyvumą, todėl „Nvidia“ teigė, kad keičiamas ir tvirtas roboto mokymasis yra daug prieinamesnis ir efektyvesnis.
LAPA vamzdynas veikia per trijų pakopų procesą:
- Latentinis veiksmų kiekybinis nustatymas: Vektoriaus kiekybinis variacinis autocoderio (VQ-VAE) modelis išmoksta atskiras „latentinius veiksmus“ analizuodamas perėjimus tarp vaizdo rėmų, sukurdamas atominio elgesio, tokio kaip sugriebimas ar pilamas, žodyną. Latentiniai veiksmai yra žemo matmens, išmoktos reprezentacijos, apibendrinančios sudėtingą robotų elgesį ar judesius, todėl lengviau valdyti ar imituoti aukšto matmens veiksmus.
- Latentinis išankstinis rašymas: VLM yra iš anksto apmokytas naudojant elgesio klonavimą, kad būtų galima numatyti šiuos latentinius veiksmus iš pirmojo etapo, remiantis vaizdo stebėjimais ir kalbos instrukcijomis. Elgesio klonavimas yra metodas, kai modelis išmoksta nukopijuoti ar imituoti veiksmus, atvaizduojant stebėjimus su veiksmais, naudojant pavyzdžius iš demonstracinių duomenų.
- Robotas po treniruotės: Tada iš anksto apdorotas modelis yra išmokytas, kad būtų galima prisitaikyti prie tikrų robotų, naudojant mažą etiketę duomenų rinkinį, žemėlapį latentinius veiksmus su fizinėmis komandomis.
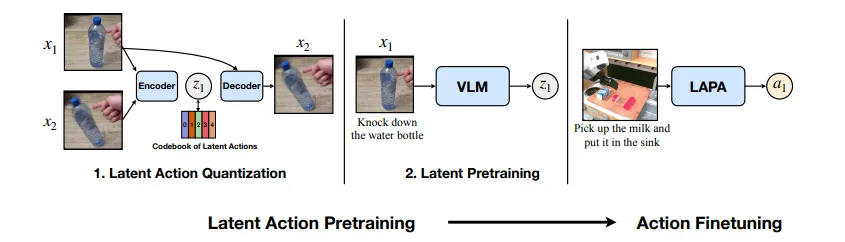
Latentinio veiksmo išankstinio pranešimo apžvalga. | Šaltinis: NVIDIA
„Sim“ ir „Real“ mokymo darbo eiga
Robotų politikos mokymai susiduria su dviem kritiniais iššūkiais: didelėmis realaus pasaulio duomenų rinkimo ir „realybės atotrūkio“ kaupimo išlaidomis, kai tik modeliavimo politika dažnai nesugeba atlikti gerai realioje fizinėje aplinkoje.
„Sim-and real“ mokymo darbo eiga nagrinėja šias problemas, derinant nedidelį realaus pasaulio robotų demonstracijų rinkinį su dideliais modeliavimo duomenų kiekiais. Šis požiūris leidžia mokyti tvirtą politiką, tuo pačiu efektyviai sumažinti išlaidas ir užpildyti realybės spragą.
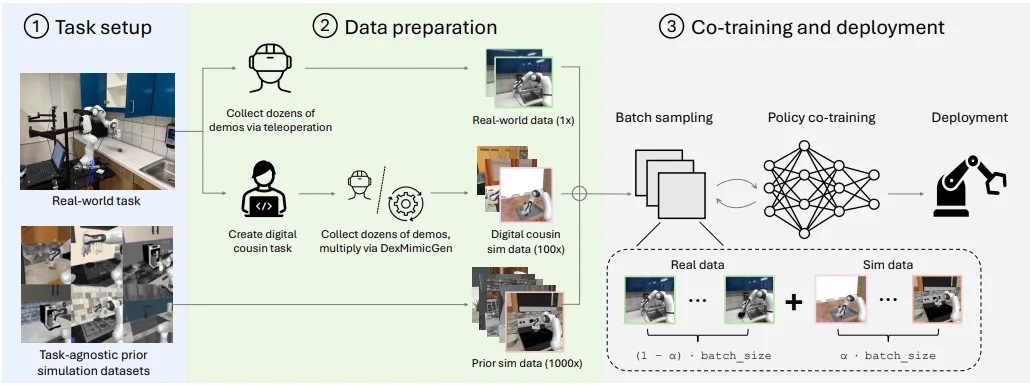
Įvairių duomenų gavimo etapų apžvalga. | Šaltinis: NVIDIA
Pagrindiniai darbo eigos žingsniai yra šie:
- Užduoties ir scenos sąranka: Realaus pasaulio užduoties nustatymas ir užduoties agnostinių ankstesnių modeliavimo duomenų rinkinių pasirinkimas.
- Duomenų paruošimas: Šiame duomenų paruošimo etape realaus pasaulio demonstracijos renkamos iš fizinių robotų, o sukuriamos papildomos modeliuojamos demonstracijos, tiek kaip užduotis, tiek kaip užduotis „skaitmeniniai pusbroliai“, kurie glaudžiai atitinka tikrąsias užduotis, ir kaip įvairius, agnostinius išankstinius modeliavimus.
- Bendras parametrų derinimas: Tada šie skirtingi duomenų šaltiniai yra sumaišyti esant optimizuotam bendrojo mokymo santykiui, pabrėžiant fotoaparatų požiūrio suderinimą ir maksimaliai padidinti modeliavimo įvairovę, o ne fotorealizmą. Paskutiniame etape apima paketinių atrankos ir politikos mokymus naudojant realius ir imituotus duomenis, todėl robote yra tvirta politika.

Modeliavimo ir realaus pasaulio užduočių vaizdas. | Šaltinis: NVIDIA
Kaip parodyta žemiau esančiame paveikslėlyje, padidinus realaus pasaulio demonstracijų skaičių, galite pagerinti tiek realios, tiek kartu apmokytos politikos sėkmės procentą. Net ir turėdama 400 realių demonstracijų, bendra parengta politika vidutiniškai 38 proc. Nuosekliai pralenkė realią politiką, parodydama, kad bendras mokymas SIM ir realu išlieka naudingas net ir turtingose duomenyse.
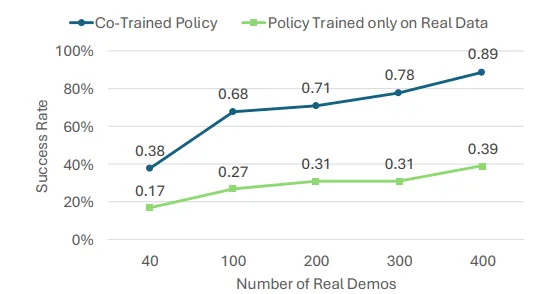
Diagrama, rodanti bendrai apmokytos politikos veiklą ir politiką, apmokytą tik realius duomenis. | Šaltinis: NVIDIA
Robotikos ekosistema pradeda priimti naujus modelius
Pagrindinės organizacijos priima šias NVIDIA tyrimų darbo eigas, kad paspartintų plėtrą. Ankstyvieji GR00T N modelių įvaikintojai apima:
- „Aeirobot“: Modelių naudojimas, kad jos pramoniniai robotai galėtų suprasti natūralią kalbą sudėtingoms rinkimo ir vietos užduotims.
- „FoxLink“: panaudojimas modeliams, siekiant pagerinti savo pramoninių robotų ginklų lankstumą ir efektyvumą.
- Šviesos ratas: Sintetinių duomenų, skirtų greičiau diegti humanoidinius robotus gamyklose, patvirtinimas naudojant modelius.
- „Neura Robotics“: modelių įvertinimas, skirtas pagreitinti savo buitinių automatizavimo sistemų plėtrą.
 Apie autorių
Apie autorių
 Apie autorių
Apie autorių„Oluwaseun Doherty“ yra techninės rinkodaros inžinieriaus stažuotoja NVIDIA, kur jis dirba robotų mokymosi programose „Nvidia Isaac Sim“, „Isaac Lab“ ir „Isaac Gr00T“ platformose. Šiuo metu Doherty siekia informatikos bakalauro laipsnio Pietryčių Luizianos universitete, kur daugiausia dėmesio skiria duomenų mokslui, AI ir robotikai.
Redaktoriaus pastaba: Šis straipsnis buvo sindikuotas iš NVIDIA techninio tinklaraščio.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}