











„Liquid Ai“ teigė, kad su savo pagrindų modeliais tikisi pasiekti optimalią balansą tarp kokybės, latencijos ir atminties konkrečioms užduotims ir aparatinės įrangos reikalavimams. | Šaltinis: skysčio AI
Šią savaitę „Liquid AI“ išleido „LFM2“ – „Liquid Foundation“ modelį (LFM), kuris, pasak bendrovės, nustato naują kokybės, greičio ir atminties efektyvumo panaudojimo standartą.
Didelių generatyvinių modelių perkėlimas iš tolimų debesų iki lieknų, įrengtų LLMS atrakina milisekundės latentinį latenciją, atsparumą neprisijungus ir privatumui duomenų privatumui. Tai yra galimybės telefonams, nešiojamiesiems kompiuteriams, automobiliams, robotams, nešiojimams, palydovams ir kitiems galiniams taškams, kurie turi būti pagrįsti realiuoju laiku.
„Liquid AI“ suprojektavo modelį, kad būtų užtikrinta greita „Gen-Ai“ įrenginių patirtis visoje pramonėje, atrakindamas didžiulį daugybę prietaisų, skirtų generuojamam AI darbo krūviui. Sukurtas ant naujos hibridinės architektūros, LFM2 pristato dvigubai greitesnį iššifravimą ir priešpakalbių našumą kaip „Qwen3“ CPU. Tai taip pat žymiai pralenkia modelius kiekvienoje dydžio klasėje, todėl jie yra idealūs efektyviems AI agentams maitinti, sakė bendrovė.
Kembridžo, Masačusetes įsikūrusios įmonės, teigė, kad dėl šių rezultatų padidėjimo LFM2 yra idealus pasirinkimas vietiniams ir krašto naudojimo atvejams. Be naudos diegimui, naujoji architektūra ir mokymo infrastruktūra tris kartus pagerina mokymo efektyvumą, palyginti su ankstesne LFM karta.
„Liquid AI“ įkūrėjas ir MIT kompiuterių mokslo ir dirbtinio žvalgybos laboratorijos (CSAIL) įkūrėjas ir direktorius Daniela Rus pristatė pagrindinį pranešimą „Robotics Summit & Expo 2025“-robotikos plėtros renginyje, kurį sukūrė robotų ataskaita.
LFM2 modelius šiandien galima įsigyti „Hugging Face“. „Liquid AI“ išleidžia juos pagal atvirą licenciją, kuri yra pagrįsta „Apache 2.0“. Licencija leidžia vartotojams laisvai naudoti LFM2 modelius akademiniams ir tyrimų tikslais. Bendrovės taip pat gali naudoti modelius komerciškai, jei jos yra mažesnės (mažiau nei 10 mln. USD pajamų).
„Liquid AI“ siūlo mažus multimodalinius pamatų modelius su saugiu įmonės klasės diegimo krūvu, kuris kiekvienam įrenginiui paverčia AI įrenginiu vietoje. Tai, pasak jos, suteikia galimybę įsigyti didelę rinkoje esančią dalį, nes įmonės pasuka nuo „Cloud LLMS“ į ekonomišką, greitą, privačią ir privačią intelektą.
https://www.youtube.com/watch?v=vmibynqrs9y
Ką gali padaryti LFM2?
„Liquid Ai“ teigė, kad LFM2 treniruojasi tris kartus greičiau, palyginti su ankstesne karta. Tai taip pat naudinga iki du kartus greitesnio iššifravimo ir priešpildinio greičio procesoriuje, palyginti su „Qwen3“. Be to, bendrovė teigė, kad LFM2 pralenkia panašaus dydžio modelius įvairiose etaloninėse kategorijose, įskaitant žinias, matematiką, instrukcijas ir daugiakalbes galimybes.
LFM2 yra aprūpinta nauja architektūra. Tai yra hibridinis skysčio modelis su daugybiniais vartais ir trumpais konvoliacijomis. Jį sudaro 16 blokų: 10 dvigubo trumpo nuotolio konvoliucijos blokų ir 6 blokai sugrupuotos užklausos dėmesio.
Nesvarbu, ar jis naudojamas išmaniuosiuose telefonuose, nešiojamuose kompiuteriuose ar transporto priemonėse, LFM2 efektyviai veikia CPU, GPU ir NPU aparatinėje įrangoje. Bendrovės pilno statinio sistema apima architektūros, optimizavimo ir diegimo variklius, kad paspartintų kelią nuo prototipo iki produkto.
Skystis AI išleidžia trijų tankių kontrolės taškų svorius su 0,35b, 0,7b ir 1,2b parametrais. Vartotojai gali juos išbandyti dabar skystoje žaidimų aikštelėje, apkabindami veidą ir „OpenRouter“.
Kaip LFM2 veikia prieš kitus modelius?
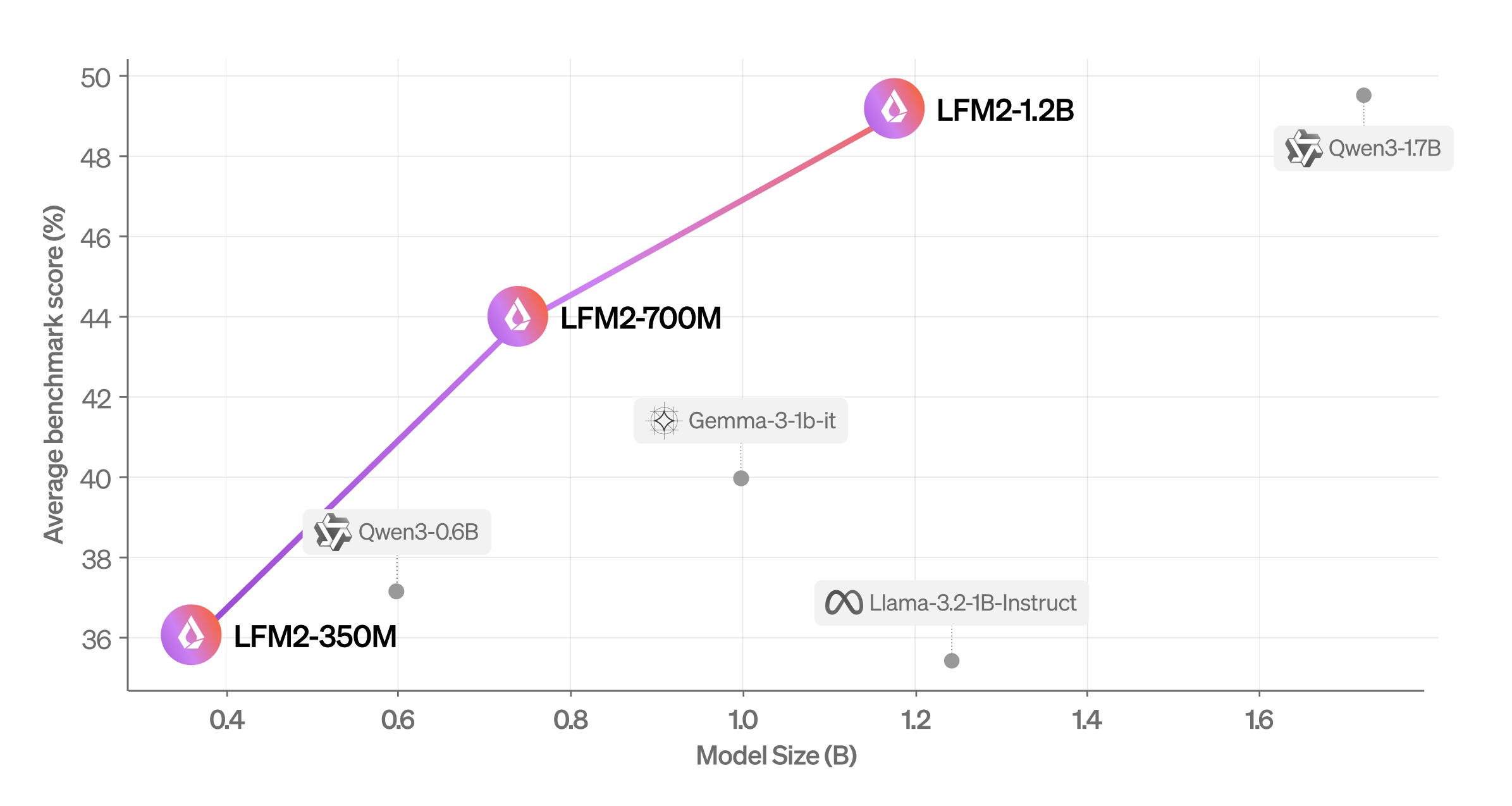
Vidutinis balas (mmlu, ifeval, ifbench, gsm8k, mmmlu) palyginti su modelio dydžiu. | Šaltinis: skysčio AI
Bendrovė įvertino LFM2, naudodama automatinius etalonus ir LLM-as-A-teismo sistemą, kad gautų išsamią savo galimybių apžvalgą. Jis nustatė, kad modelis pralenkia panašaus dydžio modelius skirtingose vertinimo kategorijose.
Liquid AI also evaluated LFM2 across seven popular benchmarks covering knowledge (5-shot MMLU, 0-shot GPQA), instruction following (IFEval, IFBench), mathematics (0-shot GSM8K, 5-shot MGSM), and multilingualism (5-shot OpenAI MMMLU, 5-shot MGSM again) with seven languages (Arabic, French, German, Spanish, Japanese, Korean, ir kinų).
Jis nustatė, kad LFM2-1.2B veikia konkurencingai su „QWEN3-1.7B“-modeliu, kurio parametrų skaičius yra 47% didesnis. „LFM2-700M“ pralenkia „Gemma 3 1B IT“, o jo mažiausias kontrolės taškas LFM2-350M yra konkurencingas su QWEN3-0.6B ir LLAMA 3.2 1B instrukcija.
Kaip skystas AI treniravo LFM2
Siekdama treniruotis ir padidinti LFM2, bendrovė pasirinko tris modelio dydžius (350 m, 700 m ir 1,2b parametrus), nukreipdama į mažo latentinį diskusijos kalbų modelio darbo krūvius. Visi modeliai buvo mokomi 10T žetonų, iš kurių paimti iš prieš mokymo korpuso, sudarė maždaug 75% anglų kalbos, 20% daugiakalbių ir 5% kodo duomenys, gaunami iš žiniatinklio ir licencijuotų medžiagų.
Dėl daugiakalbių LFM2 galimybių įmonė daugiausia dėmesio skyrė japonų, arabų, korėjiečių, ispanų, prancūzų ir vokiečių kalboms.
Išankstinio mokymo metu skystis AI panaudojo esamą LFM1-7B kaip mokytojo modelį žinių distiliavimo sistemoje. Bendrovė naudojo kryžminę entropiją tarp LFM2 studentų rezultatų ir LFM1-7B mokytojo išvestų kaip pagrindinį mokymo signalą per visą 10T prieigos rakto mokymo procesą. Konteksto ilgis buvo pratęstas išankstinio apdailos metu iki 32K.
Po treniruotės prasidėjo labai didelio masto prižiūrimų derinimo (SFT) etape įvairiuose duomenų mišinyje, kad būtų galima atrakinti generalines galimybes. Šiems mažiems modeliams įmonei buvo naudinga tiesiogiai treniruotis reprezentaciniame paskesnių užduočių rinkinyje, pavyzdžiui, skudurų ar funkcijų skambučiuose. Duomenų rinkinį sudaro atvirojo kodo, licencijuoti ir tiksliniai sintetiniai duomenys, kai įmonė užtikrina aukštą kokybę derinant kiekybinius pavyzdžių taškus ir kokybinę euristiką.
Liquid AI papildomai taiko pasirinktinį tiesioginio pasirinkimo optimizavimo algoritmą, kai normalizuojama ilgio, naudojant neprisijungusius duomenis ir pusiau rindinius duomenis. Pusiau vienaląsčio duomenų rinkinys generuojamas imant daugybę jo modelio užpildų, pagrįstų „Seed SFT“ duomenų rinkiniu.
Tada bendrovė įvertina visus atsakymus su LLM teisėjais ir sukuria pirmenybių poras, derindama aukščiausią ir žemiausią įvertintą SFT ir Policy pavyzdžių užpildymą. Tiek neprisijungę, tiek pusiau vienaląsčiai duomenų rinkiniai yra toliau filtruojami atsižvelgiant į balų slenkstį. Skystis AI sukuria kelis kandidatų kontrolės taškus keičiant hiperparametrus ir duomenų rinkinių mišinius. Galiausiai jis sujungia geriausius savo kontrolės punktų pasirinkimą į galutinį modelį, naudojant skirtingus modelio sujungimo metodus.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}