












„VIDAR“ įkūnijo AI modelį iš „Shengshu“, o ne fizinių treniruočių duomenys naudoja modeliuojamus pasaulius. Šaltinis: „Adobe Stock“, „VectorHub“ pagal ledą
„Shengshu Technology Co.“ vakar išleido savo daugialypės peržiūros fizinio AI mokymo modelį „Vidar“, kuris reiškia „Vaizdo difuzija veiksmų pagrindimui“. Naudodamas „Vidu“ galimybes semantiniame ir vaizdo supratime, „Vidar“ naudoja ribotą fizinių duomenų rinkinį, kad imituotų roboto sprendimų priėmimą realaus pasaulio aplinkoje, sakė bendrovė.
„„ Vidar “siūlo radikaliai kitokį požiūrį į mokymą įkūnyti AI modelius“, – teigė „Shengshu“ technologija. „Kaip ir„ Tesla “daugiausia dėmesio skiria regėjimui pagrįstai mokymui, o Waymo pasvira į„ LiDAR “, pramonė tiria skirtingus kelius į fizinę AI.“
Įkurta 2023 m. Kovo mėn., „Shengshu Technology“ specializuojasi daugiamodalinių didelių kalbų modelių (LLMS) plėtroje. Pekine įsikūrusi įmonė teigė, kad ji teikia mobilumo kaip paslaugos (MAAS) ir programinės įrangos kaip paslaugos (SaaS) produktus, skirtus protingesniams, greitesniems ir labiau keičiamoms turinio kūrimui.
Savo pavyzdine vaizdo įrašų kartos platforma „Vidu“, Shengshu teigė, kad ji pasiekė vartotojus daugiau nei 200 šalių ir regionų visame pasaulyje, apimančioje sritis, įskaitant interaktyvias pramogas, reklamą, filmus, animaciją, kultūrinį turizmą ir dar daugiau.
VIDAR imituojo mokymą, siekiant pagreitinti robotų plėtrą
„Nors kai kurios kompanijos moko fizinę AI įterpdamos modelius į realaus pasaulio robotus ir renka duomenis per fizinę sąveiką, su kuria susiduria jų robotai, tai yra brangus, nuo aparatinės įrangos priklausomo ir sunkiai masto metodas“,-sakė „Shengshu Technology“. „Kiti remiasi grynai imituojamais mokymais, tačiau tai dažnai trūksta kintamumo ir kraštų atvejų duomenų, reikalingų realiojo pasaulio diegimui.“
Vidaras laikosi kitokio požiūrio, tvirtino bendrovė. Tai sujungia ribotus fizinio rengimo duomenis su generatyviniu vaizdo įrašu, kad būtų galima numatyti ir sukurti naujus hipotetinius scenarijus, sukuriant kelių vaizdo modeliavimą, kuriame vaizduojama gyvybinga mokymo aplinka, esanti virtualioje erdvėje. Tai leidžia atlikti tvirtesnius, keičiamus mokymus be laiko, išlaidų ar fizinio pasaulio duomenų rinkimo apribojimų, paaiškino Shengshu.
Sukurtas „Vidu“ generacinio vaizdo modelio viršuje, „VIDAR“ gali atlikti dvigubos rankos manipuliavimo užduotis su kelių vaizdo įrašų prognozėmis ir netgi reaguoti į natūralios kalbos balso komandas po tiksliai derinant. Modelis iš tikrųjų yra skaitmeninės smegenys realaus pasaulio veiksmams, sakė įmonė.
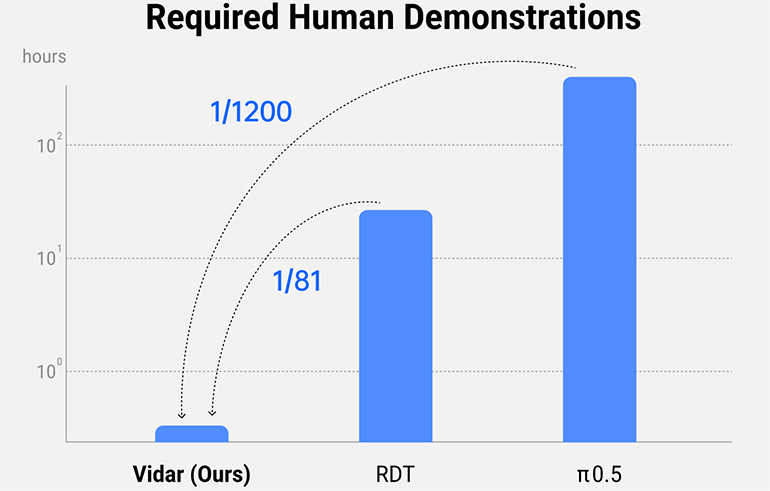
Naudodamas „Vidu“ generalinį vaizdo variklį, „Vidar“ generuoja didelio masto modeliavimą, kad sumažintų priklausomybę nuo fizinių duomenų, išlaikant sudėtingumą ir turtingumą, reikalingą norint treniruotis realaus pasaulio turinčiam AI agentams. Shengshu teigė, kad „Vidar“ gali ekstrapoliuoti apibendrintą robotų veiksmų seriją ir užduotis tik iš 20 minučių mokymo duomenų. Bendrovė tvirtino, kad yra nuo 1/80 iki 1/1200 duomenų, reikalingų pramonės pirmaujančių modelių, įskaitant RDT ir π0.5, treniruotis.
Shengshu teigė, kad pagrindinė Vidaro naujovė slypi jos modulinėje dviejų pakopų mokymosi architektūroje. Skirtingai nuo tradicinių metodų, kurie sujungia suvokimą ir kontrolę, „Vidar“ juos atskiria į du skirtingus etapus, kad būtų didesnis lankstumas ir mastelio keitimas.
Aukščiausio lygio etape didelio masto bendrieji vaizdo duomenys ir vidutinio masto įkūnyti vaizdo duomenys naudojami VIDU suvokimo supratimo modeliui treniruoti.
Antrajame pasroviui pasroviui, užduočių agnostinis modelis pavadino bet kokį vaizdinį supratimą į robotų variklio komandas. Šis atskyrimas leidžia žymiai lengviau ir greičiau treniruotis ir dislokuoti AI įvairių tipų robotus, tuo pačiu sumažinant sąnaudas ir didinant mastelį.
„Vidar“ yra skirtas sumažinti mokymo duomenų kiekį, reikalingą AI modeliams treniruoti. Šaltinis: „Shengshu“ technologija.
„Vidar“ keičiamo įkūnyto intelekto sistema
„Vidar“ seka keičiamą mokymo sistemą, įkvėptą praėjusio AI proveržio kalbos ir vaizdų pagrindų modelių. „Shengshu“ teigė, kad jo trijų pakopų duomenų piramidė, apimanti didelio masto bendrąjį vaizdo įrašą, įkūnytus vaizdo duomenis ir konkrečiai robotams būdingus pavyzdžius, sudaro lankstesnę sistemą, sumažinant tradicinį duomenų kliūtį.
Pastatytas ant „U-Vit“ architektūros, kurioje tiriamas difuzijos modelių ir transformatorių architektūrų suliejimas, skirtas plačiam daugiamodalinės generavimo užduotims, „Vidar“ dirba ilgalaikį laiko modeliavimą ir daugiapakopį vaizdo nuoseklumą, kad būtų galima fiziškai pagrįsti sprendimų priėmimą.
Šis dizainas palaiko greitą perkėlimą iš modeliavimo prie realaus pasaulio diegimo, kuris, pasak Shengshu, yra labai svarbus robotikai dinaminėje aplinkoje. Anot bendrovės, tai taip pat sumažina inžinerinį sudėtingumą
Shengshu teigė, kad „Vidar“ gali palengvinti robotikos priėmimą įvairiuose sektoriuose. Nuo namų padėjėjų ir pagyvenusių žmonių priežiūrų iki intelektualios gamybos ir medicininės robotikos modelis leidžia greitai prisitaikyti prie naujų aplinkų ir kelių užduočių scenarijų-visi su minimaliais duomenimis, pridūrė.
„VIDAR“ sukuria AI-Native kelią robotikos plėtrai, kuri yra veiksminga, keičiama ir ekonomiškai efektyvi, tvirtino Shengshu. Pertvarkydama bendrąjį vaizdo įrašą į veiksmingą robotų intelektą, bendrovė teigė, kad jos modelis gali užpildyti atotrūkį tarp vaizdinio supratimo ir įkūnytos agentūros.

VIDAR turi modulinę mokymosi architektūrą. Šaltinis: „Shengshu“ technologija
„Shengshu“ žymės multimodalinės AI gairės
„Vidar“ remiasi greitu „Vidu Video Foundation“ modelio pagreičiu, sakė Shengshu. Bendrovė išvardijo statistiką nuo debiuto:
- „Vidu“ per mėnesį pasiekė 1 milijoną vartotojų
- Per tris mėnesius pranoko 10 milijonų vartotojų
- Sukūrė daugiau nei 100 milijonų vaizdo įrašų iki 4 mėnesio
- Nuorodos į vidų karta viršijo 100 milijonų per mėnesį
- Iš viso sugeneruoti vaizdo įrašai dabar 300 milijonų
Shengshu toliau plečiasi multimodalinės AI sienas, „Vidar“ žymi kitą sieną – sujungia apibendrinimą, generatumą ir įkūnijimą į vieną vieningą sistemą.
Redaktoriaus pastaba: „Robobusiness 2025“, kuris vyks spalio 15 ir 16 dienomis Santa Klaroje, Kalifornijoje, apims kūrinius apie fizinę AI ir humanoidinius robotus. Registracija dabar atidaryta.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}