











GR00T N1 yra vizijos, kalbos ir veiksmo modelio pavyzdys. Šaltinis: NVIDIA
Robotika tradiciškai naudoja modulinius vamzdynus. Suvokimas, planavimas ir valdymas yra atskirose sistemose ir jungiasi per rankiniu būdu suderintas sąsajas. Šis metodas tinka paprastoms, tiksliai apibrėžtoms užduotims. Jai sunku, kai keičiasi aplinka arba kai robotai turi laikytis lanksčių nurodymų. Vision-language-action arba VLA modeliai siūlo kitokį kelią.
Tokios sistemos kaip „Figure AI's Helix“, „NVIDIA“ GR00T N1 ir „Google DeepMind“ RT-1, pristatytos praėjusiais metais, sujungia regėjimą, kalbos supratimą ir variklio valdymą į vieną modelį. Šios sistemos veikia nuo galo iki galo ir tiesiogiai veikia tikrus robotus.
Šis pakeitimas dabar svarbus, nes pastaruoju metu atliktas darbas rodo praktinį diegimą įrenginyje. Tai gali sumažinti delsą, pagerinti miklumą ir leisti greičiau pakeisti užduotis. VLA nukreipia į robotus, kurie supranta natūralias instrukcijas, atlieka kelių etapų užduotis ir sklandžiai juda be trapių, rankomis statomų vamzdynų.
Pažiūrėkime, kaip veikia VLA, palyginkime pagrindinius metodus ir išnagrinėkime komercinių robotų komandų aparatinę įrangą, diegimą ir saugos aspektus.
Kas yra vizijos-kalbos-veiksmo modeliai?
Vizijos, kalbos ir veiksmo modeliai yra vieningos AI sistemos, kurios sujungia viziją, kalbos supratimą ir veiksmus į vieną galutinį modelį. VLA priima vaizdus (arba vaizdo įrašus) ir kalbos instrukcijas bei sukuria nuolatines variklio komandas, kurios lemia roboto elgesį fiziniame pasaulyje.
Šis metodas skiriasi nuo tradicinės robotikos. Senesnės sistemos padalino suvokimą, planavimą ir valdymą į atskirus modulius. Inžinieriai juos sieja su rankomis sukurtomis taisyklėmis, kurios dažnai nepavyksta netvarkingoje ir lanksčioje aplinkoje.
VLA remiasi vizijos kalbos modeliais (VLM), pridedant veiksmų. Jie daro daugiau nei atpažįsta scenas ar atsako į klausimus. Jie nusprendžia, kaip robotas turi judėti, sugriebti ir manipuliuoti objektais.
Vykdydami bendrą regėjimo, semantikos ir motorinio elgesio mokymą, VLA išmoksta bendrų vaizdų, kurie palaiko lankstų užduočių vykdymą. Šis pagrindas tiesiogiai veda į pagrindines VLA architektūras, kurios dabar skatina sparčią autonominės robotikos pažangą.

Pagrindinės architektūros skatina vizijos, kalbos ir veiksmų pažangą
Kelios naujausios vizijos, kalbos ir veiksmo architektūros rodo, kaip ši nauja paradigma pereina nuo tyrimų prie veikiančių robotų sistemų. Kiekvienas eina skirtingu keliu link suvokimo, kalbos ir veiksmo vienijimo.
Helix – aukšto dažnio gudrus valdymas
Helix yra VLA modelis, kurį sukūrė „Figig AI“, kad būtų galima valdyti visą viršutinę humanoidinių robotų kūno dalį. Jis dideliu dažniu nukreiptas į rankas, rankas, liemenį ir pirštus.
Helix naudoja dviejų sistemų dizainą. Didelis vizijos kalbos pagrindas užtikrina aukšto lygio samprotavimus ir užduočių supratimą. Atskira, greita visuomotorinė politika tuos vidinius vaizdus paverčia nuolatiniais valdymo signalais.
Šis padalijimas leidžia „Helix“ apibendrinti užduotis, tuo pat metu tenkinant gudraus manipuliavimo realiuoju laiku poreikius nestruktūrizuotoje aplinkoje.
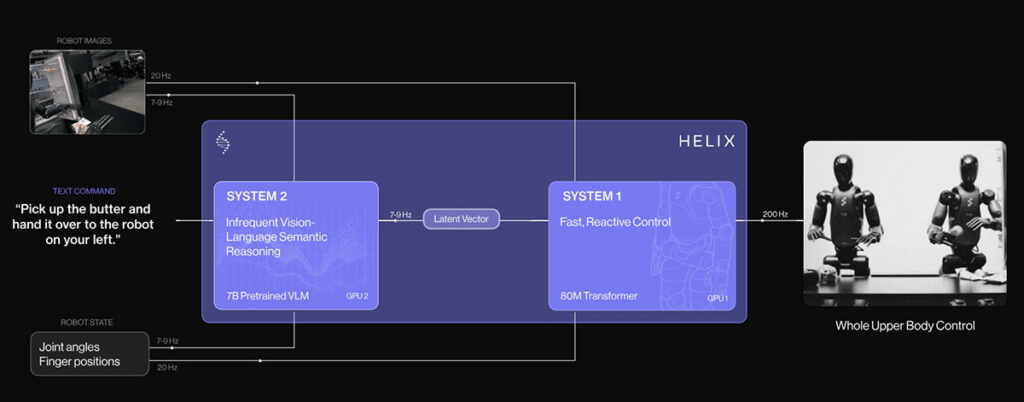
Helix architektūra. Šaltinis: paveikslas AI
GR00T N1 – atviras, generalistinis robotikos pagrindo modelis
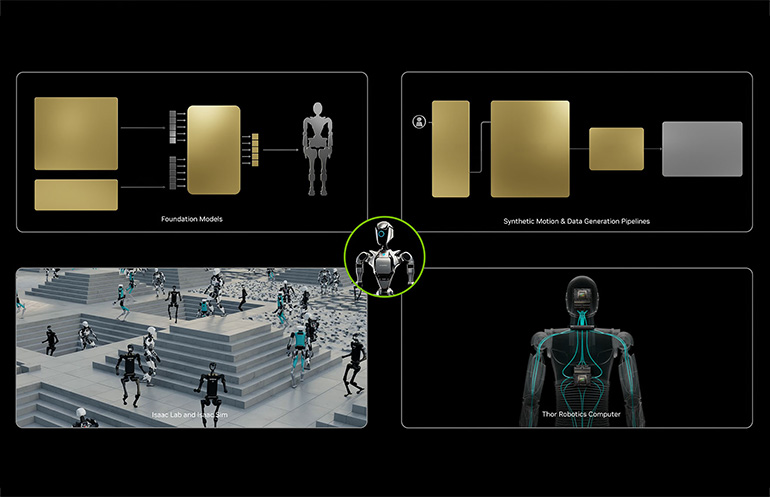
GR00T N1, kurį pristatė NVIDIA, vadovaujasi robotikos pagrindo modeliu. Jis mokomas neprisijungus, naudojant robotų trajektorijas, demonstruojamus žmones ir sintetinius duomenis. Tikslas yra platus apibendrinimas tarp užduočių ir robotų platformų.
NVIDIA parodė, kad GR00T N1 veikia tikra humanoidine aparatūra, įskaitant manipuliavimą dviem rankomis. Kaip ir dideli kalbų modeliai (LLM), pabrėžiamas išankstinis mokymas vieną kartą ir platus pritaikymas.
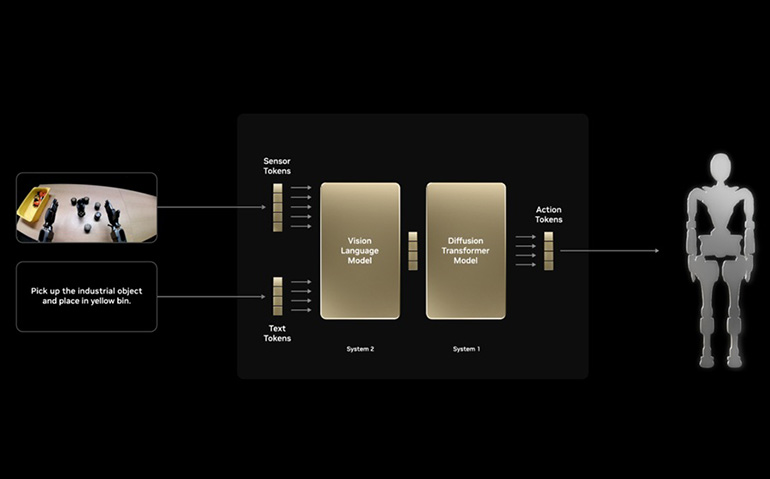
GR001 N1 modelio architektūra. Šaltinis: NVIDIA
RT-2 – keičiamo dydžio įkūnytas AI
RT-2, iš Google DeepMind, išplečia Gemini 2.0 daugiarūšį pagrindą į nuolatinį veiksmų valdymą. Tai demonstruoja stiprų apibendrinimą nematytų objektų ir kelių žingsnių užduotims. Naujausi įrenginio variantai sumažina delsą ir palaiko darbą neprisijungus.
Kartu šie metodai sudaro sąlygas, kaip VLA integruojasi su fiziniais robotų krūvais.
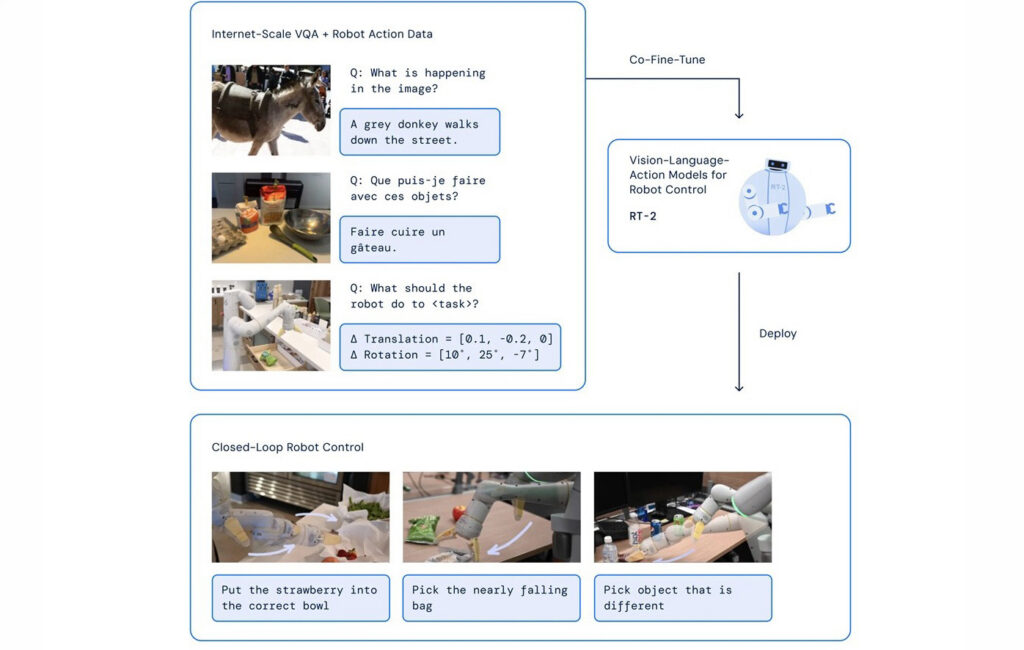
RT-2 architektūra. Šaltinis: Google DeepMind
Kaip VLA integruojasi su fiziniais robotų krūvais
Vaizdo, kalbos ir veiksmo modeliai remiasi turtingu, sujungtu jutimu. RGB ir gylio kameros, lidar, IMU ir jėgos / sukimo momento jutikliai maitina daugiarūšius koduotuvus, todėl modelis realiu laiku mato geometriją, tekstūrą ir kontaktų būsenas.
Integruotas skaičiavimas formuoja tai, kas įmanoma. Daugiarūšių transformatorių realaus laiko išvadoms atlikti reikalingi GPU arba specializuoti greitintuvai. Priešingu atveju delsa sumažina saugumą ir reagavimą.
Tai sukuria kompromisą: paleiskite VLA vietoje, kad būtų mažas delsos laikas ir darbas neprisijungus, arba naudokite hibridinę debesies sąranką, kad galėtumėte rimčiau samprotauti ir atnaujinti modelius. Įrenginyje esantis RT-2 variantas iliustruoja vietinį požiūrį, sumažina tinklo vėlavimą ir leidžia greičiau reaguoti.
Toliau išnagrinėsime praktinius diegimo iššūkius ir svarstymus, su kuriais turi susidurti komercinės komandos, priimdamos VLA.
Praktiniai diegimo iššūkiai ir svarstymai
Nors VLA žada transformacinius gebėjimus, realus diegimas vis dar susiduria su sunkiais iššūkiais.
Realaus pasaulio tvirtumas
Realaus pasaulio tvirtumas išlieka pagrindine kliūtimi. VLA gali būti trapūs, kai keičiasi apšvietimas, netvarkingos scenos arba jutikliai praneša apie triukšmingus duomenis. Norint užtikrinti patikimą elgesį įvairiose aplinkose, reikia atlikti išsamius bandymus ir užtikrinti saugumą.
Aparatinės įrangos apribojimai – šilumos, energijos suvartojimas ir ryšio pralaidumas – gali dar labiau apriboti mobiliųjų robotų veikimą.
Efektyvumas ir modelio dydis
Taip pat svarbu efektyvumas ir modelio dydis. Dideli VLA modeliai apkrauna integruotus išteklius. Naujas darbas su mažesniais, efektyviais variantais (pvz., kompaktiškų VLA modelių tyrimai) rodo, kad paprastesnės architektūros vis dar gali suteikti prasmingą konkrečių užduočių valdymą.
Lyginamoji analizė ir standartai
Kuriami lyginamoji analizė ir standartai. Tokiose konferencijose kaip ICLR pastebimas VLA tyrimų antplūdis, tačiau šioje srityje trūksta plačiai pripažintų etalonų ir bandymų rinkinių, kad būtų galima teisingai įvertinti tiek modeliavimo, tiek tikrų robotų atvejus.
Kur krypsta VLA tyrimai ir pramonė
Žvelgiant į ateitį, vizijos, kalbos ir veiksmų tyrimai rodo aiškų pagreitį. Kita banga sutelkta į gilesnes daugiarūšes ir įkūnytas AI sistemas, kurios peržengia šiandienos dizainą.
Architektūroje atsiranda vienas didelis poslinkis. Tyrėjai dabar tyrinėja difuzija pagrįstus ir hibridinius modelius, o ne grynai autoregresyvią politiką. Šie metodai efektyviau generuoja veiksmų sekas ir suderina samprotavimus su kontrole, o tai pagerina užduočių apibendrinimą.
Kita tendencija sutelkta į įkūnytą pažinimą. Nauji modeliai susieja nuolatinį suvokimą su laiko suvokiamu veiksmų planavimu ir tarpiniu samprotavimu. Tai padeda robotams suprasti kontekstą ilgesniu laikotarpiu ir patikimiau atlikti kelių etapų užduotis.
Ekosistema taip pat greitai plečiasi. Atviros sistemos ir bendrinami duomenų rinkiniai, pvz., bendruomenės skatinamos pastangos, tokios kaip LeRobot, palengvina eksperimentavimą ir skatina laboratorijų ir įmonių bendradarbiavimą. Kartu šios tendencijos rodo VLA, kurios geriau plečiasi, greičiau prisitaiko ir mato platesnį pritaikymą komercinėje robotikoje.
Praktiškas žingsnis link tikrai autonomiškų robotų
Vizijos, kalbos ir veiksmo modeliai žymi aiškų pertrauką nuo senesnių, modulinių robotikos vamzdynų. Jie sujungia suvokimą, kalbos supratimą ir valdymą vienoje sistemoje, todėl robotai gali interpretuoti instrukcijas ir veikti daug lanksčiau.
Komercinėms robotikos komandoms šis pokytis atveria duris natūralios kalbos sąsajoms, stipresniam užduočių apibendrinimui ir robotams, kurie žmonių erdvėse veikia natūraliau.
Manau, kad VLA yra praktiškas žingsnis link mašinų, kurios tikrai supranta, ką ir kaip daryti. Tačiau sėkmė priklauso nuo apgalvoto pritaikymo, kuris subalansuoja ambicingus pajėgumus su techninės įrangos apribojimais, saugos reikalavimais ir realaus pasaulio diegimo apribojimais.
 Apie autorę
Apie autorę
 Apie autorę
Apie autoręPratik Shinde yra „Omdena“ turinio ir SEO ekspertas ir pilnas skaitmeninės rinkodaros specialistas, turintis daugiau nei šešerių metų patirtį, skatinančią natūralų SaaS, AI ir technologijų prekių ženklų augimą. Jis laikosi holistinio požiūrio į rinkodarą, derindamas SEO, turinio strategiją, mokamą įsigijimą ir dirbtinio intelekto automatizavimą, kad pasiektų išmatuojamus verslo rezultatus.
Anksčiau Shinde vadovavo didelio poveikio SEO ir nuorodų kūrimo iniciatyvoms kelioms pasaulinėms SaaS įmonėms, padėdamas joms padidinti autoritetą, srautą ir konversijas konkurencingose rinkose.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}